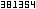Overview
This patch provides for a way to securely move where core files show up and to
set the name pattern for core files to include the UID, Program, Hostname, and/or
PID of the process that caused the core dump. This is very handy for diskless
clusters where all of the core dumps go to the same disk and for production
servers where core dumps want to be segregated from the main production disks.
This also makes it easier to clean up core files since you would no longer need
hunt through the whole filesystem looking for files named "core".
Background and how it works
What I did with this patch is provide a new sysctl that lets you control the
name of the core file. This name is actually a format string such that
certain values from the process can be included. If the sysctl is not used to
change the format string, the behavior is exactly the same as the current kernel
coredump behavior. (The default pattern is set to "core" which
produces the same result as the current kernels do - thus you can use the sysctl
to even put back the current behavior if you change it - the current behavior is
not a special case)
The sysctl is kernel.core_name_format and is a string up to 63 characters (plus
1 for the null)
The following format options are available in that string:
%P |
|
The Process ID (current->pid) |
%U |
|
The UID of the process (current->uid) |
%N |
|
The command name of the process (current->comm) |
%H |
|
The nodename of the system (system_utsname.nodename) |
%% |
|
A "%" |
For example, in my clusters, I have an NFS R/W mount at /coredumps that all
nodes have access to. The format string I use is:
sysctl -w "kernel.core_name_format=/coredumps/%H-%N-%P.core"
This then causes core dumps to be of the format:
/coredumps/whale.sinz.org-badprogram-13917.core
Another possible use it to collect core dumps for specific hosts or programs in
their own directories. For example:
echo "/cores/%N/%H.core" > /proc/sys/kernel/core_name_format
would put coredumps into something like:
/cores/badprogram/whale.sinz.org.core
Note that only programs that have directories already created in /cores would
get their cores saved as the coredump process will not create a directory.
Another form would be to just name the core dumps based on the program name but
still put them into the current working directory. For example:
sysctl -w "kernel.core_name_format=%N-%P.core"
would put, into CWD, files of the form:
The flexibility in the format string lets you define the behavior you need in
your environment.
I used upper case characters to reduce the chance of getting confused with
format() characters and to be somewhat similar to the mechanism that exists on
FreeBSD.
Compatibility
The default name format is set to "core" to match the current
behavior of the kernel. Old behavior of appending the PID to the "core"
name is also preserved with added logic of only doing so if the PID is not
already part of the name format. This fully preserves current behaviors within
the system while still providing for the full control of the format of the core
file name. Current behavior is not a special case but "falls out" of the
general case when the format is set to "core".
I have the patch for Linux
2.4.19 and Linux 2.5.40
but should patch relatively cleanly to other versions. I tried to comment the
code a bit to explain the how and why. (I hope not too much :-)
Some notes on security:
This patch does add the ability of a system administrator to make a core dump
format string that could cause problems. If the format string is set to be a
fixed file name of say, "/bin/sh" it would be a "bad thing" to have
a core dump happen :-)
There is always the problem of someone with root access making a bad setting in
the sysctl. But then, if they have root, they don't need to set some sysctl in
order to cause damage.
However, I have also worked through the security and reliability of the code
assuming that the system administrator does not set a blatantly bad pattern. In
addition to the standard prevention of buffer over-runs and the like, I also
make sure that any user adjustable input gets filtered to remove "/" characters
such that directories can not be changed via a program name of, say "../foo/x" (assuming
that some program goes and changes its process name to that)
So it does not prevent someone from making a name format that would be bad (such
as "/bin/sh" or "/usr/bin/%N") but then "rm -rf"
still works too :-)
One thing that I do feel is very good about this is that you can now segregate
your core files to a different partition and thus prevent the writing to and/or
filling up of your important partitions. For the diskless clusters that I am
building, it also provides a way to track who caused the core dump and, in our
cluster, a place to write it since all of the other disks are read-only or /dev/tmpfs
devices.
|